logstash: usando múltiplos pipelines
É comum termos casos de uso onde precisamos receber dados de diversas fontes no logstash que terão tratamentos e destinos diferentes, por isso é importante isolar os eventos de cada fonte de dado.
Antes da versão 6.X o logstash só permitia um único pipeline em execução, então quando era necessário separar os eventos de fontes de dados diferentes, duas abordagens eram comumente utilizadas:
- executar múltiplas instâncias
- utilizar condicionais nos filtros e outputs
Embora ambas resolvam o problema, a primeira exige mais recursos da máquina já que cada instância corresponde a uma JVM diferente. A segunda abordagem se tornaria mais problemática em casos com muitas fontes de dados diferentes, o que levaria a uma quantidade grande de condicionais no pipeline, aumentando assim a probabilidade de algum erro na configuração.
A partir da versão 6.X se tornou possível executar múltiplos pipelines nativamente, bastando para isso apenas configurar o arquivo pipelines.yml do logstash. Dessa forma um único processo do logstash é executado e os pipelines são completamente isolados um do outro.
configurando múltiplos pipelines
A definição dos pipelines que serão executados pelo logstash é feita através do arquivo pipelines.yml, é nele que definimos as características de um pipeline como o nome, a localização da configuração, a quantidade de workers que serão utilizados, o tipo de fila e outras configurações específicas.
Quando o logstash é executado como serviço ou via linha de comando sem argumentos, o arquivo pipelines.yml será lido e os pipelines serão inicializados, caso os argumentos -e ou -f sejam utilizados na linha de comando, o arquivo será ignorado.
Por padrão, quando instalado via .rpm ou .deb, o arquivo pipelines.yml vem configurado com um pipeline genérico chamado main.
- pipeline.id: main
path.config: "/etc/logstash/conf.d/*.conf"
Na configuração acima, a chave pipeline.id define qual o nome do pipeline e a chave path.config define a localização da configuração do pipeline, o valor dessa chave pode tanto apontar diretamente para um arquivo quanto para um diretório com vários arquivos que serão combinados na inicialização do pipeline.
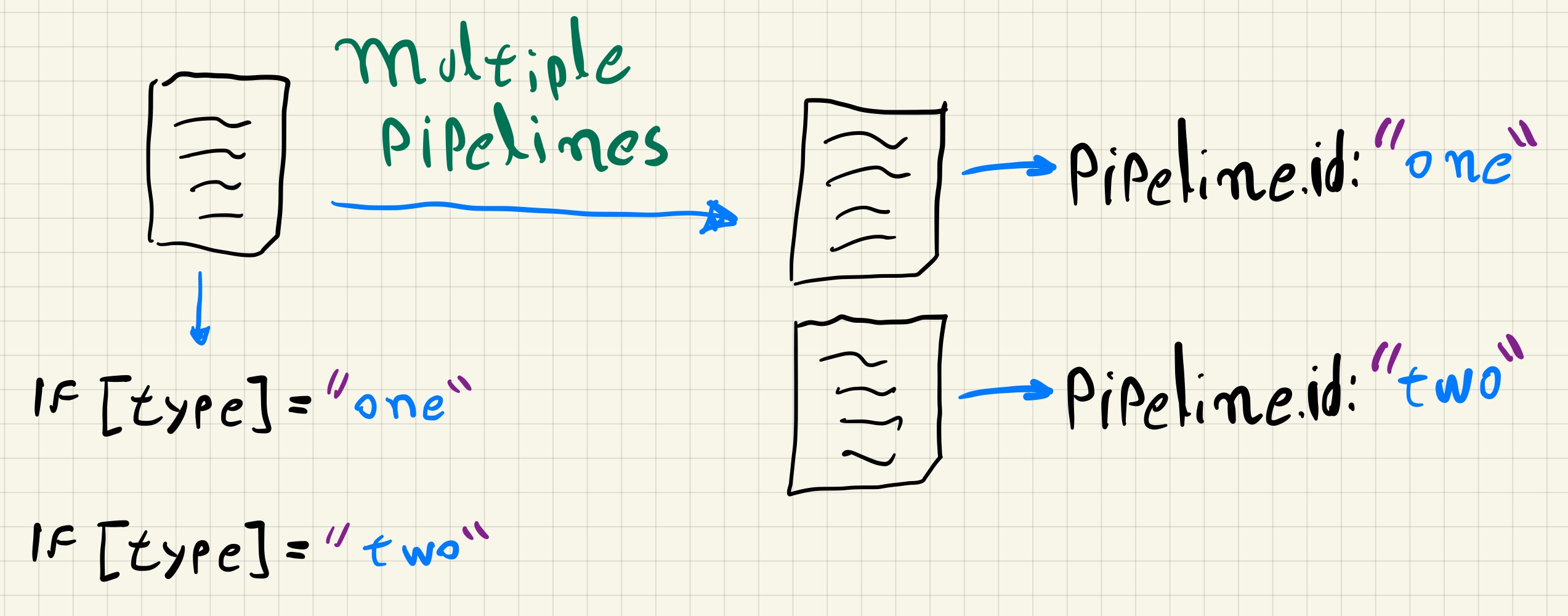
Considerando um exemplo onde temos que receber dados via beats e via udp, se não utilizarmos múltiplos pipelines precisaremos filtrar os eventos utilizando algum campo específico.
Se para os eventos do tipo beats adicionarmos o campo type com o valor “one” e para os eventos do tipo udp adicionarmos o campo type com o valor “two”, a configuração abaixo permite que os eventos dos pipelines sejam processados de forma isolada nos blocos de filtro e output.
input {
beats {
port => 5001
type => "one"
}
udp {
port => 2514
type => "two"
}
}
filter {
if [type] == "one" {
filtros para os eventos beats
} else if [type] == "two" {
filtros para os eventos udp
}
}
output {
if [type] == "one" {
output para os eventos beats
} else if [type] == "two" {
output para os eventos udp
}
}
Para utilizarmos múltiplos pipelines nesse exemplo, precisamos alterar tanto o arquivo pipelines.yml quanto criar os arquivos de configuração de cada pipeline.
No arquivo pipelines.yml seriam definidos os pipelines.
- pipeline.id: "one"
path.config: "/etc/logstash/conf.d/one.conf"
- pipeline.id: "two"
path.config: "/etc/logstash/conf.d/two.conf"
E os arquivos de configuração teriam a estrutura dos modelos a seguir.
/etc/logstash/conf.d/one.conf
input {
beats { port => 5001 }
}
filter {
filtros para os eventos beats
}
output {
output para os eventos beats
}
/etc/logstash/conf.d/two.conf
input {
udp { port => 5001 }
}
filter {
filtros para os eventos udp
}
output {
output para os eventos udp
}
vantagens e outras configurações
Além da vantagem de permitir uma melhor organização dos pipelines, separando diferentes tipos de dados em diferentes fluxos de ingestão, o uso de múltiplos pipelines permite também que cada um deles tenha configurações específicas, buscando uma otimização no uso dos recursos disponíveis.
Por exemplo, quando executamos o logstash em um servidor que tem 8 cores, por padrão cada pipeline utilizará 1 worker por núcleo de CPU para realizar o processamento nos blocos de filtro e output, mas podemos ter pipelines que são bem simples e podem ser executados tranquilamente utilizando apenas 1 ou 2 workers.
Podemos também querer utilizar fila em memória para alguns pipelines e fila em disco para outros, ou alterar o tamanho da batch de envio de eventos para um pipeline específico, com os pipelines separados temos a flexibilidade de alterar essas configurações isoladamente.
Continuando com o exemplo onde temos um pipeline beats e um pipeline udp, vamos considerar que o pipeline beats não precisa de fila persistente em disco e precisa rodar com 8 workers, 1 para cada núcleo de CPU, já o pipeline udp precisaria de uma fila em disco, mas poderia ser executado com apenas 2 workers.
- pipeline.id: "one"
path.config: "/etc/logstash/conf.d/one.conf"
- pipeline.id: "two"
path.config: "/etc/logstash/conf.d/two.conf"
path.queue: "/caminho/para/fila/persistente"
queue.type: persisted
pipeline.workers: 2
Podemos ver que para o pipeline one não fizemos nenhuma alteração, pois o tipo de fila padrão já é em memória e o número de workers também utilizará o padrão, 1 worker para cada núcleo de cpu.
Já no pipeline two, foi preciso definir o tipo de fila e o caminho para o armazenamento e também o número de workers.
Caso uma configuração não seja definida no arquivo pipelines.yml ela irá utilizar o valor padrão ou o valor definido no arquivo logstash.yml.
A documentação oficial sobre múltiplos pipelines no logstash pode ser encontrada neste link e as opções de configuração para cada pipeline podem ser encontradas neste outro link.