logstash: otimizando desempenho
Introdução
Já tem um tempo que utilizo a pilha da elastic pra coletar e armazenar logs de aplicações, serviços e dispositivos que preciso monitorar. Sendo o Logstash o responsável em receber, tratar e publicar os logs, garantir que ele tenha um bom desempenho é extremamente importante.
Boa parte dos problemas de desempenho que enfrentei estavam relacionados a erros de configuração, implantação ou uso incorreto de alguns filtros, principalmente o filtro grok.
Embora o grok seja extremamente útil, ele é um filtro baseado em expressões regulares e que precisa validar cada expressão configurada, dependendo do número de eventos por segundo essas validações podem acabar gerando uma grande carga na CPU da máquina do Logstash, o que pode impactar em todo o processo de monitoramento.
Grok ou Dissect?
Uma forma simples de otimizar o desempenho de um pipeline é verificar a possibilidade de utilizar outro filtro no lugar do grok. Um filtro que eu venho utilizando bastante como substituto é o dissect.
A principal diferença entre o grok e o dissect é que o dissect não utiliza expressões regulares para analisar a mensagem, os campos são definidos a partir de sua posição, tudo que estiver entre um %{ e um } é considerado um campo e todo o resto é considerado um delimitador, isso torna o dissect mais rápido que o grok e também exige menos processamento durante a análise.
Considere o exemplo de mensagem a seguir:
2020-08-20T21:45:50 127.0.0.1 [1] program.Logger INFO - sample message
Podemos extrair dessa mensagem os seguintes campos:
timestamp,ipaddr,thread,logger,loglevel,msg

Para analisarmos essa mensagem com o grok e dissect usamos as seguintes configurações.
grok
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{IP:ipaddr} \[%{INT:thread}\] %{DATA:logger} %{WORD:loglevel} - %{GREEDYDATA:msg}"}
}
dissect
dissect {
mapping => {
"message" => "%{timestamp} %{ipaddr} [%{thread}] %{logger} %{loglevel} - %{msg}"
}
}
Perceba que a estrutura é bem semelhante, mas no grok precisamos especificar contra qual expressão regular iremos validar o campo, como por exemplo TIMESTAMP_ISO8601 para o campo timestamp ou IP para o campo ipaddr, algo que não temos no dissect , já que o filtro irá armazenar como valor do campo o que estiver naquela posição na mensagem e isso acaba sendo um dos fatores que influencia na escolha de um ou outro.
Se as mensagens coletadas em um pipeline possuem sempre a mesma estrutura, ou até mesmo poucas variações, o uso do dissect no lugar do grok se faz possível e se mostra vantajoso, já que a análise será mais rápida e precisará de menos processamento.
Mas será que é mesmo mais rápido e usa menos processamento?
Grok vs Dissect
Para comparar o desempenho dos dois filtros utilizei um pipeline simples usando como input o filtro generator e como output o filtro stdout, e alternei o uso dos filtros grok e dissect exemplificados anteriormente.
input {
generator {
lines => ["2020-08-20T21:45:50 127.0.0.1 [1] program.Logger INFO - sample message"]
count => 10000000
}
}
filter {
#
# filtro de grok ou dissect
#
if [sequence] != 0 and [sequence] != 9999999 {
drop { }
}
}
output {
stdout { }
}
Esse pipeline basicamente gera 10 milhões de mensagens, aplica o filtro especificado no momento, grok ou dissect, e faz um drop na mensagem, exceto a primeira e a última, que são exibidas apenas para verificar o início e fim do processamento.
A saída desse pipeline é a seguinte.
{
"host" => "elk",
"ipaddr" => "127.0.0.1",
"message" => "2020-08-20T21:45:50 127.0.0.1 [1] program.Logger INFO - sample message",
"sequence" => 0,
"loglevel" => "INFO",
"logger" => "program.Logger",
"@version" => "1",
"timestamp" => "2020-08-20T21:45:50",
"msg" => "sample message",
"thread" => "1",
"@timestamp" => 2020-08-26T02:00:38.127Z
}
{
"host" => "elk",
"ipaddr" => "127.0.0.1",
"message" => "2020-08-20T21:45:50 127.0.0.1 [1] program.Logger INFO - sample message",
"sequence" => 9999999,
"loglevel" => "INFO",
"logger" => "program.Logger",
"@version" => "1",
"timestamp" => "2020-08-20T21:45:50",
"msg" => "sample message",
"thread" => "1",
"@timestamp" => 2020-08-26T02:02:34.018Z
}
Como estava interessado em comparar o processamento da máquina durante a execução dos filtros, utilizei o nmon rodando em background e coletando métricas a cada 1 segundo, durante 5 minutos, o que resulta em 300 medidas, uma quantidade mais do que suficiente para esse caso.
Para a execução do pipeline utilizei uma máquina virtual com 4 vCPUs e 4 GB de RAM rodando o CentOS 7.8 e o Logstash na versão 7.9.
Cada medida gerada pelo nmon tem o seguinte formato.
ZZZZ,T0010,00:16:49,21-AUG-2020
CPU001,T0010,50.5,2.0,0.0,46.5,1.0
CPU002,T0010,99.0,0.0,0.0,1.0,0.0
CPU003,T0010,97.0,1.0,0.0,1.0,1.0
CPU004,T0010,96.0,1.0,0.0,3.0,0.0
CPU_ALL,T0010,86.4,0.8,0.0,12.8,0.0,,4
MEM,T0010,3789.0,-0.0,-0.0,1024.0,2903.2,-0.0,-0.0,1024.0,-0.0,281.9,577.3,-1.0,2.0,0.0,181.5
VM,T0010,30,0,0,2384,12760,-1,0,0,0,0,27,0,0,2541,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
PROC,T0010,5,0,2524.7,-1.0,-1.0,-1.0,1.0,-1.0,-1.0,-1.0
NET,T0010,2.6,0.1,2.8,0.1
NETPACKET,T0010,10.9,2.0,12.9,2.0
JFSFILE,T0010,59.0,0.0,0.5,59.0,24.3,4.5,4.5,4.5
DISKBUSY,T0010,0.0,0.0,0.0,0.0
DISKREAD,T0010,0.0,0.0,0.0,0.0
DISKWRITE,T0010,0.0,0.0,0.0,0.0
DISKXFER,T0010,0.0,0.0,0.0,0.0
DISKBSIZE,T0010,0.0,0.0,0.0,0.0
De todas essas linhas, somente a linha CPU_ALL importa, mais especificamente a terceira coluna que corresponde ao percentual de uso médio de todas as CPUs no momento da coleta.
Fazendo uma manipulação dos dados coletados durante a execução do pipeline com o grok e depois com o dissect podemos visualizar e comparar o consumo de CPU e o tempo de execução.
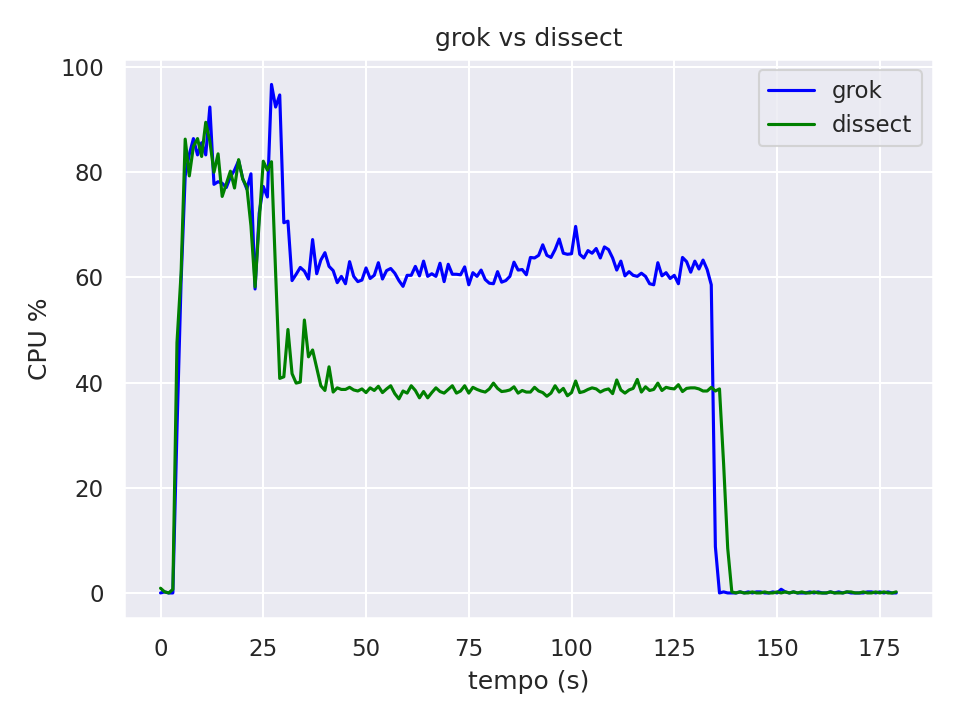
O pico inicial de processamento que vemos no gráfico é causado pela inicialização do Logstash, o platô seguinte corresponde ao processamento durante a análise das mensagens.
Analisando o gráfico vemos que o tempo para processar as 10 milhões de mensagens é basicamente o mesmo para os dois filtros testados nesse caso específico, mas temos uma diferença grande no processamento. Uma média de uso de CPU de 40% quando utilizamos o filtro dissect em comparação com uma média de uso de CPU de mais de 60% quando utilizamos o filtro grok.
Conclusão e Links
Dependendo do número de pipelines e da quantidade de eventos por segundo de cada um deles, dedicar um tempo para validar a possibilidade de troca do filtro grok pelo dissect é algo que pode otimizar bastante o desempenho durante o processo de análise e ingestão de dados, além de poder também refletir em redução de custos quando se tem uma infraestrutura em nuvem já que possibilita tanto o uso de máquinas menores, quanto menos consumo de créditos de cpu em alguns casos.
Nos casos onde os logs coletados seguem sempre a mesma estrutura, como acontece com logs de servidores web, servidores de aplicação, firewalls e roteadores, ou onde se tem controle sobre o formato dos logs gerados, o dissect é o filtro ideal quando se utiliza o Logstash no processo de coleta e análise de logs.
Links
dissect: documentação oficialgrok: documentação oficial